
Introduction
An acronym is a pronounceable word created from the first letter of each word in a phrase or title. An acronym is a kind of abbreviation consisting of a first letter or initial letters in a word. It’s also called short descriptors of phrase.
Interesting Fact: Acronym was introduced as a modern linguistic element of English during the 1950s. Because acronym is called a term, its meaning is called expansion.
Usage & Challenges
An acronym is primarily used in language processing, web search, ontology mapping, question answering, text messaging, and social media sharing. Acronyms evolve each day dynamically, and finding their definition/expansion becomes a daunting task due to its diverse characteristics. Several researchers experimented with plain text and network expansion pairs for mining acronyms over the past two decades. Manually edited online archives have pairs of acronyms, but regularly reviewing all possible meanings is intimidating.
Solution
To handle this issue, TVS Next has built a specialized product to extract acronyms from a document in a few seconds. This product is built on Python for Natural Language Processing.
Below are some pointers that describe how our research works that help us solve the problem mentioned above.
Heuristics Approach
NLP (Natural Language Processing) and pattern-based methods include heuristics.
- The NLP-based approach uses a fuzzy-matching Statistical Model based on the principles of Levenshtein’s Distance algorithm.
- The pattern-based approach uses custom rules that work with data from multiple domains, combined with Statistical Modelling to extract the Acronyms and their Expansions. These methods are written after considering features in the text as characteristics of acronyms – ambiguity, nesting, uppercase letters, length, and para-linguistic markers.
An Acronym Finding Program (AFP) is a simple, free-text expansion recognition method. This program applies an inexact matching algorithm for mining AE pairs. A tool known as Three Letter Acronym (TLA) uses para-linguistic markers such as parenthesis, commas, and periods to derive acronym meaning from technical and government documents.
Developing the Product
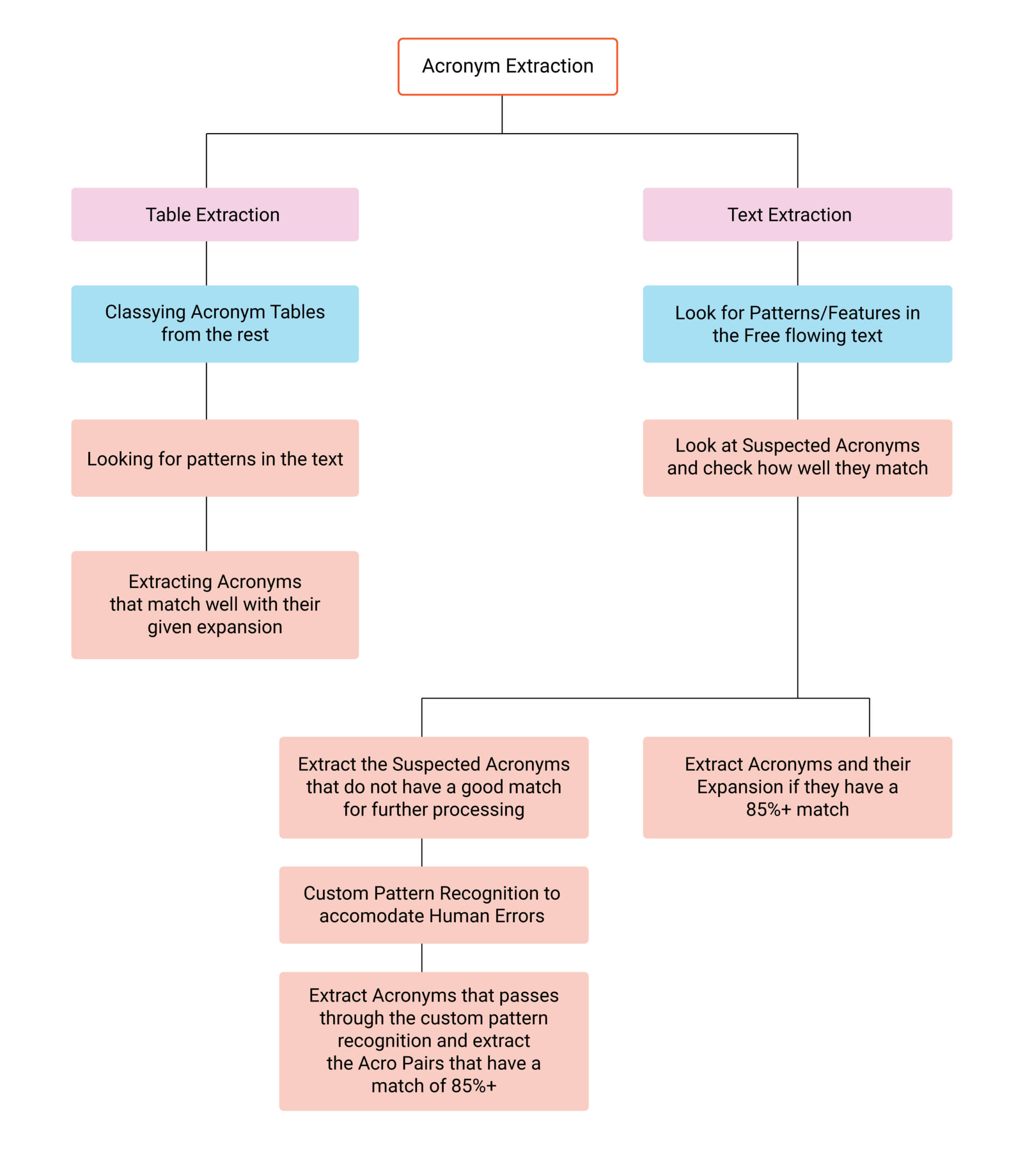
A Statistical model has created to provide the user with a Solution that gives ease of access to acronyms that appear throughout the document. The designed solution can be integrated into various tools and technologies that deal with text-based information. The solution proves to be useful while combining it with tools that parse PDF documents. It deals with – tables, free-flowing text.
A document consists of multiple tables that are very similar in structure; hence our solution uses a Table Classification method to differentiate the acronym table from the rest. Various types of Statistical Methods were incorporated to quantify features/patterns that help define what an acronym will look like. This solution was used to classify an acronym table from the rest and then extract acronyms from the table.
For free-flowing text, a similar technique has been used where the patterns/features of an acronym are incorporated to differentiate it from the rest of the free-flowing text. There are words extracted that can turn out to be acronyms. These words appear along with their expansion in the text. After extracting suspected acronyms, we quantify the words that consist of acronyms using statistical models and compare them to their expansions.
By enforcing the following statistical models, 80% of acronyms are obtained that are present in a document. It is essential to accommodate variations in how text is written. Simple human punctuation errors can affect the entire acronym, not falling under rules of how acronyms are generally written. A dynamic method where custom rules that works with data from multiple domains are combined along with specific Statistical Models has been implemented that will uncommonly parse texts.
On executing this dynamic method and testing various documents, we could conclude that the Statistical Model-based acronym extraction method has been performing with over 95% accuracy, even surpassing open source solutions provided by Spacy called Blackstone available in the market at the moment. Blackstone works on the techniques mentioned in a research paper written by Ariel S Schwartz et al. [2]., Multiple comparisons were made, between Blackstone and the Statistical-method based Acronym Extraction.
Result
The Statistical Model-based acronym extraction method scanned an entire document of 100+ pages in milliseconds and displayed 98% accuracy. The average time taken to scan a document is a few seconds, and the accuracy of this product has been achieved between 94-98%. The product was tested on documents belonging to various domains, and it still yielded similar results. The product is developed on an experimental basis, and we are set to improve its efficiency and performance each day. There is plenty of room for improvement with subject to market changes. The product experiments with a set of Statistical models and custom rules, and the team is working on dynamic changes using AI that scans documents based on results. This product proves to be useful for lengthy and complicated engineering and medical documents. This product is one of its kind, and we are proud of our development.
At TVS Next, we re-imagine, design, and develop software to enable our clients to build a better world.






